MySQL DISTINCT
The DISTINCT keyword can be used within an SQL statement to remove duplicate rows from the result set of a query.
Consider the following example (which doesn't use the DISTINCT option):
Result:
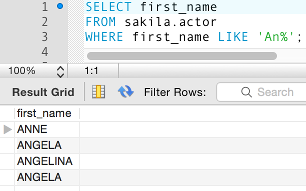
You can see that there are two records containing the value of Angela.
Now let's add the DISTINCT keyword:
Result:
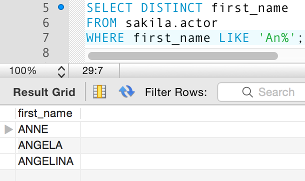
There is now only one record that contains the value of Angela. This is because the DISTINCT keyword removed the duplicates. Therefore, we know that each row returned by our query will be distinct — it will contain a unique value.
Using DISTINCT with COUNT()
You can insert the DISTINCT keyword within the COUNT() aggregate function to provide a count of the number of matching rows.
Like this:
Result:
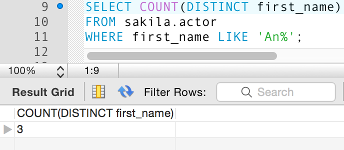
If we remove the DISTINCT option (but leave COUNT() in):
We end up with 4 (instead of 3 as we did when using DISTINCT):
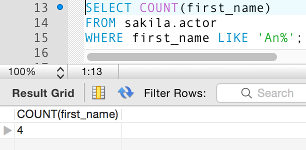
Multiple Columns
You can use DISTINCT with multiple columns. If you do select more than one column, all columns are combined to create the uniqueness of the row. This is because the DISTINCT option looks for a distinct row, rather than a distinct column.
Result:
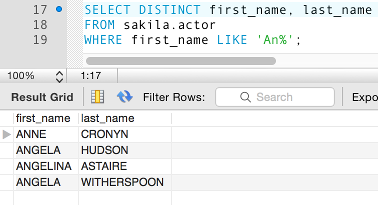
The above query returns 4 rows instead of 3, because, even though there are still two Angelas, they are now unique due to their last name being different. If they both shared the same last name, only 3 records would have been returned.
DISTINCTROW
There is also a DISTINCTROW keyword which is a synonym for DISTINCT. So you can use one or the other.
So this:
…could also be written as this:
The examples on this page use the Sakila sample database.